1
Pick a Patient Type
Select a category of patients to explore (e.g., confirmed pneumonia, normal findings, or uncertain cases).
Research Project
Explore one patient at a time. For each chest X-ray, see the model's prediction, confidence, and explanation—with full transparency about certainty and limitations.
This is a research project for methodological validation. It demonstrates rigorous approaches to model reliability, calibration, and trustworthiness. Not intended for clinical deployment without proper validation and regulatory approval.
How to Use This Demo
Trust is learned through transparency and progressive explanation.
1
Pick a Patient Type
Select a category of patients to explore (e.g., confirmed pneumonia, normal findings, or uncertain cases).
2
See the Prediction
For the selected patient, read the model's assessment: "92% chance of pneumonia" - plain English, not jargon.
3
Assess Confidence
Learn how confident we should be in that prediction based on model uncertainty and explanation stability.
4
Interpret the Explanation
See where the model focused (red heat map) and compare it to what an untrained model would see.
5
Browse Similar Cases
Use arrow buttons to explore more patients of the same type and see patterns.
6
Learn Deeper (Optional)
If interested, expand the "System Insights" section to see calibration curves and aggregate metrics.
Interactive Demo
Select a patient type, then browse one patient at a time.
This viewer uses representative random test cases with Grad-CAM overlays to mirror expected field behavior.
In this filtered set: 38 correct and 2 incorrect.
Selected patient type
Showing all patient categories.
Selected trust status
Showing all trust outcomes.
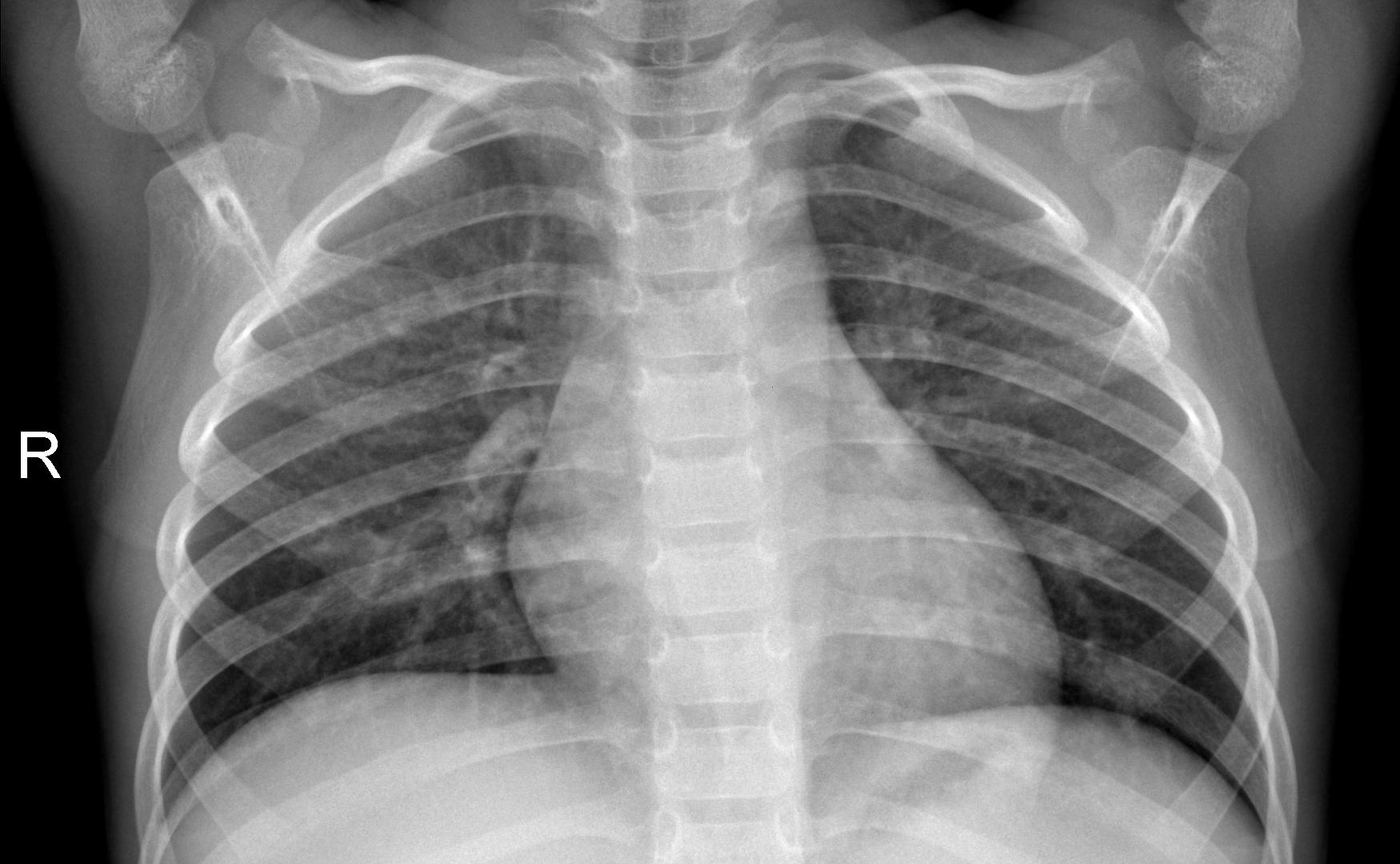
X-ray Image


Predicted diagnosis
NORMAL
Pneumonia probability: 10%
Raw confidence: 90%
Calibrated confidence: 87%
Agreement: 63%
Deterministic uncertainty: 10%
Explanation stability: 91%
Recommendation
Model should defer to manual professional review for this case.
Optional Details
Expand below to see system-wide metrics. These are useful for researchers, less so for individual patient decisions.
Conclusion
What we learned about when (and when not) to trust this model.
This model is not a replacement for expert radiologists. It is a decision-support tool, and its predictions should always be reviewed in clinical context.